|
A Multi-layer Perceptron based Non-linear Mixture Model to estimate class abundance from mixed pixels |
 |
Uttam Kumar1, 2, S. Kumar Raja5, C. Mukhopadhyay1 and T.V. Ramachandra2, 3, 4, *
Senior Member, IEEE
1 Department of Management Studies, 2 Centre for Sustainable Technologies, 3 Centre for Ecological Sciences,
4 Centre for infrastructure, Sustainable Transport and Urban Planning, Indian Institute of Science, Bangalore – 560012, India.
5 Institut de Recherche en Informatique et Systèmes Aléatoires, 35042 Rennes cedex - France & Technicolor Research & Innovation, Cesson Sévigné, France.
*Corresponding author: cestvr@ces.iisc.ac.in
|
|
|
|
Automatic linear-nonlinear mixture model
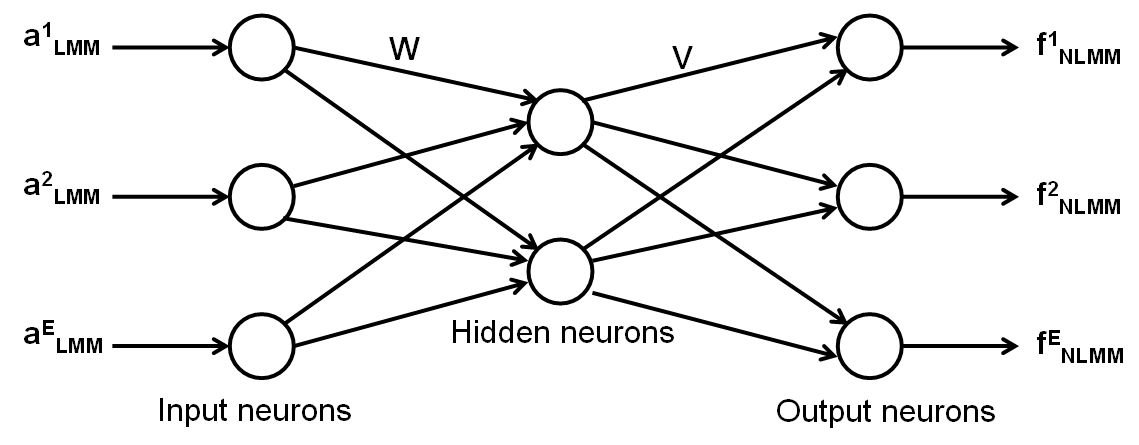
Despite many attempts of using ANN for unmixing models, ANN-based non-linear unmixing techniques remain largely unexplored for general purpose applications [20]. Only [1], [6], [8] and [21] have been some of the pioneering work in NLMM to be considered as a general model for ANN-based non-linear unmixing independent of physical properties of the observed classes. Some of these applications are however, difficult and complex in their implementation that makes LMM easy to implement, generalise and reconstruct. Therefore, in our approach, we make use of the LMM output as the input to NLMM to refine the fraction estimates. The MLP architecture can be extended to produce a continuous-values output for sub-pixel classification problem. The entries to the MLP model are the abundance (a) output obtained from LMM, which is denoted by aiLMM where i = 1, …, E, and the neuron count at the input layer equals the number of endmember classes (estimated by a fully constrained LMM) as shown in Fig. 2. The training process is based on error back-propagation algorithm [21], where the respective weights in the output and hidden nodes (W and V in Fig. 3) are modified depending on the error (δe), the input data and the learning parameter alpha (α). The activation rule used here for the hidden and output layer nodes is defined by the logistic function δe of the output layer is calculated as the difference between the fraction (f) estimation outputs fiNLMM, i = 1, … E, provided by the network architecture and a set of desired output given by actual fractional abundances available for the training samples. The resulting error is back-propagated until the convergence is reached. One of the earlier works by [20] attempted a similar NLMM methodology, which made use of a modified MLP neural network (NN), whose entries were determined by a linear activation function provided by a Hopfield NN (HNN).
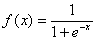 . (13) . (13)
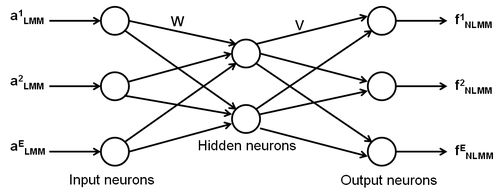
Fig. 2. Architecture of the MLP model.

Fig. 3. MLP structural diagram.
The combined HNN/MLP method used the LMM to provide an initial abundance estimation and then refined the estimation using a non-linear model. As per [20], this was the first and the only approach in the literature that integrated linear and NLMM.
|
|
Citation : Uttam Kumar, Kumar Raja. S., Mukhopadhyay. C. and Ramachandra. T.V., 2011. A Multi-layer Perceptron based Non-linear Mixture Model to estimate class abundance from mixed pixels. Proceeding of the 2011 IEEE Students' Technology Symposium 14-16 January, 2011, IIT Kharagpur., pp. 148-153.
|