|
 |
 |
|
| E Mail: cestvr@ces.iisc.ac.in , energy@ces.iisc.ac.in URL: http://ces.iisc.ac.in/energy , http://ces.iisc.ac.in/biodiversity | |||
| Synopsis Introduction Study Area Objectives Methodology Results and Discussion Acknowledgement Bibliography | Home PDF |
|
METHODOLOGY The preliminary method adopted was to collect secondary data regarding the vegetation, forest cover, topography, species diversity, landuse in the past etc. of the study area, from governmental organisations such as forest department, forest research institutes, as well as non-governmental institutes such as French Institute, Pondicherry. Data was also obtained from reviewing certain literature works, which were of significant importance to this study. Apart from these, field investigations were undertaken in order to ascertain the spectral signatures in the remotely sensed data with ground condition – type of patch, type of vegetation, etc. After collecting the essential information required for this study, the digital analysis of these data was carried out. The methodology adopted for carrying out this analysis could be categorised into 4 steps as follows:
DIGITIZATION: Survey of India (SOI) topographical maps of scale 1:50,000 and 1:2,50,000, covering all taluks of Uttara Kannada district depicting taluk boundaries, road and rail network, and drainage pattern (Figure 2) were digitized. The district boundary was digitized using toposheets 48 J, 48 I, 48 M, and 48 N each of scale 1:2,50,000. The taluk boundaries, road and rail network, and the drainage network were digitized from toposheets of scale 1:50,000. The RMS errors for digitization were checked and found to be within the acceptable limits for the scales of maps used. The lat/long coordinate system was used for digitization. Vegetation map of South India (Figure 5) of scale 1:2,50,000 was digitized using Vegetation map developed by French Institute (1984). This helps in temporal analyses to find out the changes in vegetation during the last twenty years. These digitized images (major road network and drainage network) were used to georegister and also to implement geo correction of the satellite imageries. Vector layer of the district boundary and taluk boundaries were converted to raster images in order to crop the satellite imageries, along the boundary of the study area. Figure 6: FCC of Uttara Kannada The type of forest cover in the study area was also studied during the field visits. The type of vegetation, characteristic species of the forest type, and the forested areas were assessed. The data thus obtained was used to classify the satellite imagery based on the landcover, land use and also to sub-classify based on the forest type. REMOTE SENSING DATA: Remote sensing data of IRS-1D; Path-97, Row-62, 63; LISS III sensor; 5th March 1999 and 24th April 2005 satellite imageries corresponding to Uttara Kannada district were procured from National Remote Sensing Agency (NRSA), Hyderabad. While procuring these images it was ensured that, the data obtained is of latest time scale, and image scenes have cloud cover less than 5% . Summer season data was procured to carry out landcover classification (level 1 classification – vegetation, soil, water, etc.) Land Cover Analysis: The analysis of vegetation and detection of changes in vegetation pattern are keys to natural resource assessment and monitoring. Healthy green vegetation has different trends in interaction with the energy in visible and near-infrared regions of the electromagnetic spectrum. This strong contrast between the amount of reflected energy in the red and near-infrared regions forms the basis to develop quantitative indices of vegetation condition using remotely sensed data. Various vegetation indices (VI) have been developed for qualitative and quantitative assessment of land cover. The slope-based and the distance-based vegetation indices (VIs) help in land cover analysis depending on the extent of vegetation and soil in a region. In particular, the sensors with spectral bands in the RED and NIR lend themselves well to vegetation monitoring since the difference between the red and near-infrared bands have been shown to be a strong indicator of the amount of photosynthetically active green biomass. NDVI separates green vegetation from its background soil brightness. It is expressed as the difference between the near infrared and red bands normalised by the sum of those bands, i.e. NDVI = ((NIR – RED) / (NIR + RED)) .....……(1) + This is the most commonly used VI as it retains the ability to minimise topographic effects while producing a linear measurement scale. In addition, divisions by zero errors are significantly reduced. The index normalises the difference between the bands so that the values range between -1 and +1. The negative value represents non-vegetated area while positive value represents vegetated area. Land use analysis: Classification of remotely sensed data requires the assignment of each of the pixels on an image to a class. The classification approach is based on the assumption that each of the classes on the ground has a class-specific spectral response with each of the classes varying in spectral patterns. There is substantive variation in the distribution of the pixel reflectance values depending upon where the samples are drawn within a land use type. The spectral information contained in the original and transformed bands is then used to characterise each class pattern, and to discriminate between classes. Both supervised and unsupervised classification approaches were tried to identify land use categories.SUPERVISED CLASSIFICATION: In case of supervised classification, known specific types of land-use are identified based on the spectral reflectance patterns or signatures of different features information classes. These are called training sites. With theses a statistical characterisation of reflectance for each individual class were done, which is known as signature analysis and it may be as simple as the mean or range of reflectance on each band, or as complex as analyses of variance and covariance over all bands. After the signature analysis is done the image is classified by examining the reflectance of each pixel and making a decision about which of the signature it resembles most and assigning the appropriate pixels to their respective class. This decision making and assigning of pixels to their respective classes is done by classifiers. The three most commonly used classifiers are:
Accuracy estimation in terms of producer's accuracy, user's accuracy, overall accuracy and Kappa coefficient were subsequently made after generating confusion matrix. The Kappa coefficient is a measure of the difference between the actual agreement between reference data and an automated classifier and the chance agreement between the reference data and the random classifier as shown in equation (1) and equation (2). This statistics serves as an indicator of the extent to which the percentage correct values of an error matrix are due to “true” agreement versus “chance” agreement. It incorporates the non-diagonal elements of the error matrix as a product of the row and column diagonal.
Where r = number of rows in the error matrix Of the three hard supervised classifiers, Maximum likelihood is the best and computationally difficult. The forest classes obtained were then identified as evergreen, semi-evergreen, moist deciduous, and dry deciduous. Temporal change analysis was done considering the forest cover of Uttara Kannada in 1984. Digitised Forest Map of South India generated by J.P. Pascal of the French Institute, Pondicherry (1984), was compared with the classified image obtained, by overlaying the image on the digitized map. This gave the change in the forest cover and also the forest types over a period of about fifteen years. Figure 7: NDVI of Uttara Kannada |

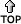
| E-mail | Sahyadri | ENVIS | Energy | GRASS | CES | IISc | E-mail |