 |
Random Forest Algorithm with derived Geographical Layers for Improved Classification of Remote Sensing Data
|
 |
1Energy and Wetlands Research Group, Centre for Ecological Sciences [CES], 2Department of Management Studies, 3Centre for Sustainable Technologies (astra),
4Centre for infrastructure, Sustainable Transportation and Urban Planning [CiSTUP],
Indian Institute of Science, Bangalore – 560012, India.
*Corresponding author: cestvr@ces.iisc.ac.in
|
RANDOM FOREST (RF)
Classifications were performed using RF technique. RF are ensemble methods using tree-type classifiers 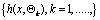 where the where the 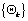 are i.i.d. random vectors and x is the input pattern. They are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. It uses bagging to form an ensemble of classification tree [15]. RF is distinguished from other bagging approaches in that at each splitting node in the underlying classification trees, a random subset of the predictor variables is used as potential variables to define split. In training, it creates multiple Classification and Regression Tree trained on a bootstrapped sample of the original training data, and searches only across randomly selected subset of the input variables to determine a split for each node. are i.i.d. random vectors and x is the input pattern. They are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. It uses bagging to form an ensemble of classification tree [15]. RF is distinguished from other bagging approaches in that at each splitting node in the underlying classification trees, a random subset of the predictor variables is used as potential variables to define split. In training, it creates multiple Classification and Regression Tree trained on a bootstrapped sample of the original training data, and searches only across randomly selected subset of the input variables to determine a split for each node.
It utilises Gini index of node impurity to determine splits in the predictor variables. For classification, each tree casts a unit vote for the most popular class at input x. The output of the classifier is determined by a majority vote of the trees that result in the greatest classification accuracy. It is superior to many tree-based algorithms, because it lacks sensitivity to noise and does not overfit.
The trees in RF are not pruned; therefore, the computational complexity is reduced. As a result, RF can handle high dimensional data, using a large number of trees in the ensemble. This combined with the fact that random selection of variables for a split seeks to minimise the correlation between the trees in the ensemble, results in error rates that have been compared to those of Adaboost, at the same time being much lighter in implementation. For more details see [9, 15-16]. Breiman and Cutler (2005) [17] suggests RF “unexcelled in accuracy among current algorithms”. RF has also outperformed CART and similar boosting and bagging-based algorithm. In the current work, RF has been implemented using a Linux based random forest package, available in R interface (http://www.r-project.org).
|
|
Citation : Uttam Kumar, Anindita Dasgupta, Chiranjit Mukhopadhyay and Ramachandra. T.V., 2011, Random Forest Algorithm with derived Geographical Layers for Improved Classification of Remote Sensing Data., Proceedings of the INDICON 2011, Engineering Sustainable Solutions, 16-18th December, Hyderabad - India, pp. 1-6.
|