2.2 Overview of Cellular Automata
| Back |
Cellular Automata (CA) plays in important role in modelling and simulation of spatio-temporal processes. CA was developed by Ulam in the 1940s and soon used by von Neumann to investigate the logical nature of self-reproducible systems (White and Engelen, 1993) and extensive experiments were done by Wolfram (2002). Later on researchers applied CA to model the geo-spatial domain, especially on urban systems (Couclelis, 1997; Batty and Xie, 1994). However, most models of spatial dynamics rest with land cover and land use change studies (Yang and Lo, 2003) and urban growth models (Batty and Xie, 1997; Batty, 1998; Clarke, et al., 1996; Couclelis, 1997; White and Englen, 1993; White, Englen and Uljee, 1997; Jianquan and Masser, 2002).
2.2 Overview of Cellular Automata |
In the geo-spatial domain, CA has been applied to urban systems with fervour and has been used to explore research questions in urban applications (Torrens, 2000). Essentially CA is a cell-based approach to model processes in a twodimensional space. Benenson and Torrens (2003) define an automaton as a discrete entity, which has some form of input and internal states. These states can change over time according to a set of rules to determine a new state in a subsequent time step. A typical CA system comprises of four components namely, cells, states, neighbourhood and rules. Cells are the smallest units of the system having adjoining neighbours. Any cell can represent a theme by its state. Like in land use map, a cell can have a state of built-up or vegetation or water bodies etc. However in CA the state of a cell can change only based on the transition rules, which are defined in terms of neighbourhood functions (Li and Yeh, 2000). Transition rules are the real engines of change in a CA (Torrens, 2000). These rules control the transformation of a cell state to another cell state over the specific period of time depending on the neighbourhood of the cells. The notion of neighbourhood is central to the CA paradigm (Couclelis, 1997).
The integration of CA with GIS has enabled a flexible framework for modelling, simulation and dynamic visualization of urban systems. A simple transition rule in a cellular automaton model is given by Li and Yeh (2000) as,
![]() Equation 1
Equation 1
with s Î S (S set of all possible cell states like, built-up or vegetation or open land, etc.). N is the neighbourhood of the cell, which acts as inputs for the transition rules. The function f defines the transition rules from time period t to t + 1 . The adjacent neighbours are defined by the cells formed by the co-ordinates {x ± 1, y ± 1} as in Moore's neighbourhood, with, x=0, y=0 as the centre cell.
Typically in a CA, the neighbourhood and the transition rules play an important role for the automaton to initiate state transitions in a cell. In most CA models, the automata are influenced only within the Moore's neighbourhood, which are the eight adjacent neighbourhood cells. Few researchers like Wolfram (2002) and White, Engelen and Uljee (1997) have explored the influence of cell states beyond the eight neighbourhood cells on the automata. Figure 2.1 depicts the notion of neighbourhood ascribed by von Neumann and Moore.

Figure 2.1: Cells and Neghirbourhood
An important notion of the CA paradigm is the geometry in two-dimension space as regular tessellated structures notably as the cells. As any typical regular tessellations, the cells are of the same size and shape, and the value attributed to the cell corresponds to the whole region bound by the cell. Other different cell geometries for regular tessellations are triangular and hexagonal cells. Even though uniformly regular spaced square cells are used as in the case of classical CA, they are unreal for realistic representation of reality (Torrens, 2000). Torrens (2000) argues that most objects in reality are not regular and hence they are not square in shape. To counter such situations irregular lattice structures are being introduced in the CA framework. In order to have congruity with the geo-spatial data obtained by remote sensing which are also in regular tessellated square or rectangular cells, the scope of the present research confines to the geometry of the cells used in CA as regularly tessellated square or rectangular cells.
Several advances are being made to explore the possibilities of the CA technique. Notable among them are calibration approaches for constrained CA models, which were applied to model geographic process (Li and Yeh, 2000; Straatman, White and Englen, 2004). These models were constrained by causal factors driving the geographical processes such as urban sprawl, wherein the availability of land and proximity to city centres and highway are without any interaction with the causal factors. According to Li and Yeh (2000), the constraints used are mainly related to land suitability according to accessibility that affects land development probability, such as cost distance to city centres, roads and railways. In their case constraints for sustainable urban development are classified into three types: local, regional and global constraints. Local constraints contain detailed spatial information for each cell, but regional constraints have only aggregated or partial-spatial information. Global constraints, however, are characterized by temporal or non-spatial information. Such an approach of defining the constraints and operating in a CA was the next step of achieving some linkages with the causal factors. However once the simulation is executed, the constraints would be static over time all through. In reality, there are situations wherein the constraints are dynamic dependent on the situations. And so it would require an ideal framework to address issues concerning the dynamics of these causal factors and constraints. Further, in such models these constraints would not behave as an event-based system with a cause-effect relationship.
Typically, the geo-spatial models need to account for the external drivers that are not accounted in the transition rules of the CA. Certain externalities can be system wide or specific to certain locations, for which the CA models have to evolve to address such requirements. Further there are possibly also different significant processes that take place in the region in question, apart from those represented in the CA model. CA models are yet incapable of representing the external factors responsible for driving the change dynamics as the transition rules account only for the states and neighbourhood. Even though certain approaches of using the constrained and state-based CA framework were suggested, these methods are not supportive of individual spatial interactions and linking dynamically directly with the externalities and constraints over time. Given that the land use / land cover change dynamics are subjected to the drivers at various scales, this multi-scale dynamics are ineffectively handled in CA. To counter such paradigm, different approaches are being suggested. Among them is the integration of agent-based models over a CA framework, as agent-based models can be constructed to represent the externalities driving the processes. Thus the current research is approaching towards the integration agent-based models (multi-agent systems) with the CA models, such as in the case of modelling the dynamics of urban sprawl by incorporating different drivers as agents involved enabling the individual spatial interactions by defining the spatial and temporal relationships to these agents.
2.3 Agents from Artificial Intelligence |
Agents, have their origins in software engineering and artificial intelligence where they are used in networking, communications and many more applications. The aim of agent design is to create a program, which interacts with its environment. The term agent' is usually applied to describe self-contained programs, which can control their own actions based on their perceptions of their operating environment. A significant definition is that, an agent is considered as a self-contained program capable of controlling its own decision-making and acting, based on its perception of its environment, in pursuit of one or more objectives. The most general way in which the term agent is used is to denote a hardware or (more usually) software-based computer system that enjoys the following properties (Wooldridge and Jennings, 1995):
• Autonomy : agents operate without the direct intervention of humans or others, and have some kind of control over their actions and internal state;
• Social ability : agents interact with other agents (and possibly humans) via some kind of agent-communication language ;
• Reactivity : agents perceive their environment, (which may be the physical world, a user via a graphical user interface, a collection of other agents, the INTERNET, or perhaps all of these combined), and respond in a timely fashion to changes that occur in it;
• Pro-activeness : agents do not simply act in response to their environment; they are able to exhibit goal-directed behaviour by taking the initiative .
There are a number of points about this definition that require further explanation. Agents are (Jennings, 2000):
• Clearly identifiable problem solving entities with well-defined boundaries and interfaces;
• Situated (embedded) in a particular environmentthey receive inputs related to the state of their environment through sensors and they act on the environment through effectors;
• Designed to fulfil a specific purposethey have particular objectives (goals) to achieve;
• Autonomousthey have control both over their internal state and over their own behaviour;
• Capable of exhibiting flexible problem solving behaviour in pursuit of their design objectivesthey need to be both reactive (able to respond in a timely fashion to changes that occur in their environment) and proactive (able to act in anticipation of future goals).
Although, the origins of agent-based models have been in the artificial intelligence, they are also developed in social sciences extensively. Amongst other application domains agent-based models are now also used for studying the urban dynamics (Portugali, Benenson and Omer, 1997; Sanders et al., 1997; Benenson 1998; Batty, 2003) over a GIS environment. Agents can be considered as a special case of an automaton, having all features of the general automaton, with a distinction that these agents are mobile and they can represent the external drivers responsible for the processes (e.g. socio-economic, population, etc.). The idea is to treat each of the individual drivers as agent-based automata enabling the spatial and temporal relationships. Supposing in the case of urban sprawl dynamics, economic activity, infrastructure availability/development, population development process, etc. are the different drivers of the process operating over the region at their respective scales in both space and time, each of these is defined as an agent-based model. There can be as many agent-based models as the number of externalities identified driving the processes at appropriate scales. Such processes take place at specific locations and are generally not system wide. While a classical CA transition rule is system wide, such agent-based models would only be specific to certain locations only. These agent-based models are to act in conjunction with the regular transition rules of the cellular automata. This integrated agent-based cellular automaton is discussed in Chapter 3.
The essential concepts of agent-based computing are agents, high-level interactions and organizational relationships (Figure 2.2). It can be seen that there can be numerous agents wherein specific agents can interact amongst themselves and/or have the same sphere of visibility and influence. There can also be agents who act independently without any interaction of other agents and unique sphere of influence.
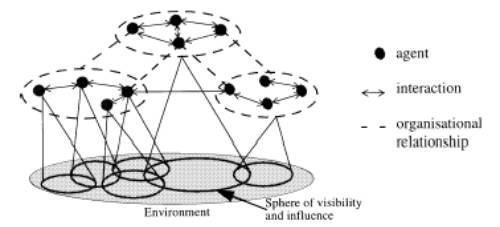
Figure 2.2: Canonical View of an Agent-based System(Jennings,2000)
2.4 Classification of Agents |
The agent ontology has been attempted in a number of ways by different investigators as per their objectives. The classifications are made based on the characteristics (autonomy, reactivity, social ability and pro-activeness) and applications of the agents. Nwana (1996) classified agents in five broad categories.
The first type of classification concerns with the mobility of these agents and so, the agents are classified as static and mobile. The next type of classification addresses the ways in which these agents are modelled. Batty and Jiang (1999) note that the ways in which the agents sense' and act' in their environment are central determinants of the behaviour which is to be modelled. Hence in this type of classification, agents are categorised as reactive' and deliberative'. The reactive agents are those agents, which is autonomous and react to its environment or to other agents. The deliberative or cognitive agents are those, which behave according to specific protocols and predefined rules. These agents need not wait for any responses but can act independently, thus emanating the autonomous characteristic of the agents.
In the third classification, agents are classified along several ideal and primary attributes, which agents should exhibit. The three characteristics autonomous, cooperation and learning are used to derive the four types of agents, viz., collaborative agents, interface agents, collaborative learning agents and smart agents (Figure 2.3).
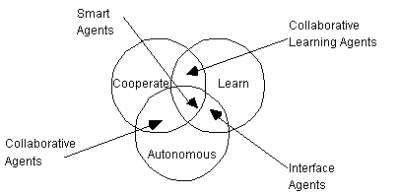
Figure 2.3 : Agent Typology (Nwana,1996)
In the fourth type of classification, the agents are classified by the roles they play like in the case of World Wide Web (WWW) as information agents. This type of agents is used in internet search engines as web crawlers and spiders. This type of agents helps in managing large amount of information over the internet. These information agents may be further classified as static, mobile or deliberative. Lastly, the combination of two or more type of agent behaviours in a single agent is termed as hybrid agents.
A significant utility of the agents in the geo-spatial modelling and simulation is that these agents can come handy where individual spatial interactions at the local level are modelled while collectively initiating the global actions, which were not well handled by the traditional CA based approaches. Few or all or a combination of the above mentioned agent-types (heterogeneous agents) can be used in the geo-spatial domain to effectively model and simulate the multi-scale dynamics at the local levels and the global level.
2.5 Tools for Agent -based Modeling |
With the intense research in the realm of agent-based modelling under the distributed artificial intelligence domain, scores of tools are developed for building ABMs, in particular by making use of the programming languages C, Objective C and Java. The development of these ABM tools came up with the academic and research institutions for applications in social simulations and studying complex behaviour. Among the earliest tool is the StarLogo, developed by the Massachusetts Institute of Technology's Media Labs. After the StarLogo, then came the SWARM, StarLogoT (a variant of StarLogo), REPAST, ASCAPE and NetLogo (from the makers of StarLogoT). The industrial circuit also has actively taken part in the developments of these agent-based tools. Notable among them are the research in International Business Machines (IBM) Corporation Limited, British Telecom and the open source project ECLIPSE. The following gives a brief description of the some of the abovementioned tools.
StarLogo: Developed by Massachusetts Institute of Technology (MIT) Media Laboratory (http://www.media.mit.edu/starlogo/), StarLogo is a programmable modelling environment for exploring the workings of decentralized systems that are self-organizing and self-coordinating. A central notion of the StarLogo is that it consists of three elements turtles as agents, patches as cells and worldview as observer. With StarLogo, it is possible to model (and gain insights into) many real-life phenomena, such as bird flocks, traffic jams, ant colonies, and market economies. StarLogo is a specialized version of the Logo programming language. With traditional versions of Logo, it is possible to create drawings and animations by giving commands to graphic "turtles" on the computer screen. StarLogo extends this idea by allowing the user to control numerous graphic turtles in parallel with patches" makes the turtles' environment.
StarLogoT: A variant of StarLogo, developed by the Centre for Connected Learning and Computer-Based Modelling, Northwestern University, USA (http://ccl.northwestern.edu/cm/starlogoT/). StarLogoT is a programmable modelling environment for building and exploring multi-level systems. It is one of a class of new "object-based parallel modelling languages" (OBPML). Currently, StarLogoT is a Macintosh-only program that lets the user to explore simulated environments. StarLogoT allows controlling the behaviour of thousands of objects in parallel. This allows one to model the behaviour of distributed and probabilistic systems, often systems that exhibit complex dynamics. StarLogoT was developed at the Tufts University Centre for Connected Learning and Computer-Based Modelling, which has since relocated to Northwestern University . It is an extended version (a superset) of StarLogo, which was developed by the MIT Media Laboratory.
SWARM: Developed by the Santa Fe Institute (http://www.santefe.edu), SWARM (http://www.swarm.org/) is a software package for multi-agent simulation of complex systems. The basic architecture of Swarm incorporates the collections of concurrently interacting agents. Swarm is essentially a collection of software libraries, written in Objective C, for constructing discrete event simulations of complex systems with heterogeneous elements or agents. Some lower-level libraries, which interface with Objective C, are also written in Tk, a scripting language that implements basic graphical tools such as graphs, windows, and input widgets.
REPAST: Stands for REcursive Porous Agent Simulation Toolkit (http://repast.sourceforge.net/), which is an open source, agent-based simulation toolkit for creating agent-based simulations using Java (1.4 or higher). RePast provides a library of classes for creating, running, displaying and collecting data from an agent based simulation. In RePast simulations the running of the simulation is divided into time steps or "ticks." Each tick some action occurs using the results of previous actions as its basis. RePast has much of the functionalities that are borrowed from the Swarm simulation toolkit and could be termed as "Swarm-like".
ASCAPE: Developed by Centre on Social and Economic Dynamics (CSED), Brookings Institution (http://www.brook.edu/es/dynamics/models/ascape/default.htm), Ascape (Agent-Landscape) is a research tool to support agent-based modelling and simulation. A high-level framework supports complex model design, while end-user tools make it possible for non-programmers to explore many aspects of model dynamics. It is written entirely in Java, and run on Java-enabled platform. Models developed within it can be easily published to the web for use with common web browsers. Sugarscape models using the ASCAPE (Epstein and Axtell, 1996: In, Batty and Jiang, 1999) demonstrate how agents are used to move over a cellular space.
NetLogo: This is a cross-platform multi-agent programmable complexity modelling environment also developed by the Centre for Connected Learning and Computer-Based Modelling, Northwestern University, USA (http://ccl.northwestern.edu/netlogo/). NetLogo comes with a large library of sample models and code examples that help beginning users get started authoring models. NetLogo is in use by research labs and university courses across a wide variety of domains in social and natural sciences.
Intelligent Agents Project at IBM T.J. Watson Research: The mission was to develop intelligent agent technology that is highly reusable and easy to integrate with a broad spectrum of networked applications. The research also contributed to company-wide efforts in strategy and in common architecture, e.g., for inter-agent knowledge-level communication and interoperability. The reusable intelligent agents technology is embodied as an extensible structured class library, called RAISE (Reusable Agent Intelligence Software Environment). RAISE is object-oriented in design and is implemented in C++. RAISE also features dynamic plugging ability of user-authored rule sets (including easy merging and updating), and development-time plugging ability of reasoning engines.
ABLE: The Agent Building and Learning Environment (ABLE) , a project made available by the IBM T. J. Watson Research Centre (http://www.alphaworks.ibm.com/tech/able), is a Java framework, component library, and productivity toolkit for building intelligent agents using machine learning and reasoning. The ABLE framework provides a set of Java interfaces and base classes used to build a library of JavaBeans called AbleBeans. The AbleBeans library contains reading and writing text and database data, data transformation and scaling, rule-based inferences (using Boolean and fuzzy logic), and machine learning techniques (such as neural networks, Bayesian classifiers, and decision trees). Developers can extend the provided AbleBeans or implement their own custom algorithms.
ZEUS: The ZEUS toolkit, which provides a library of software components and tools that facilitate the rapid design, development and deployment of agent systems. The three main functional components of the ZEUS toolkit are: the agent component library, agent building tools and the visualisation tools. The components of the agent component library implement the different aspects of agent functionality. The agent building tools provide an integrated development environment through which the agents are specified and generated. The visualisation tools enable applications to be observed and, where necessary, debugged.
JADE: Java Agent DEvelopment Framework (JADE) is a software framework to develop agent-based applications in compliance with the Foundation of Intelligent Physical Agents (FIPA - http://www.fipa.or) specifications for interoperable intelligent multi-agent systems (http://jade.tilab.com/index.html). The goal is to simplify the development while ensuring standard compliance through a comprehensive set of system services and agents. JADE can then be considered as an agent middleware that implements an Agent Platform and a development framework. It deals with all those aspects that are not peculiar of the agent internals and that are independent of the applications, such as message transport, encoding and parsing, or agent life cycle.
The abovementioned tools are not the exhaustive ones, while a detailed description of all the tools is beyond the scope of this research. A detailed description of the software and tools related to the agent-based modelling has been given by Torrens (2004) - http://www.geosimulation.org/abm/ , Testfatsion (2004) - http://www.econ.iastate.edu/tesfatsi/acecode.htm , SWARM Wiki site (2004) - http://wiki.swarm.org/wiki/Tools_for_Agent-Based_Modelling .
Although there is significant number of tools for building agent-based models, these tools are yet to evolve for applications in geo-spatial simulations. A main reason for this is that the spatial relationships or the topology and geometry have to be defined in these tools for ensuring them to handle the geo-spatial databases. The prevalent tools for building ABM are of significance only while dealing without any spatial relationships. In other sense, these agents are not bound by the geo-spatial data models. Consequently the research is attempting to define the spatial relationships for the agents modelled so that they can be used in the geo-spatial domain. In the current research NetLogo was used to develop a prototype of a hypothetical model for demonstrating the urban sprawl phenomenon in radial direction. NetLogo was favoured because it was user-friendly and supported extensive documentation for building models. The description of the prototype demonstration is dealt in Chapter 5.
2.6 CA and Agent -based Models as Distributed Simulation Systems |
A simulation is a computer program that models the behaviour of a physical system over time . The program variables or the state variables represent the current state of the physical system. Simulation program modifies state variables to model the evolution of the physical system over time. A key paradigm in the conventional simulation systems is the treatment of time. The notion of time is as per Cellier (1991) as continuous-time models, discrete-time models and discrete-event models.
In reality, the models of urban sprawl dynamics are discrete-event and discrete-time. A discrete-event simulation refers to the computer model for a system where the state variable changes at discrete points in simulation time. The essential ingredients of a discrete-event simulation are the system state or state variables and the state transitions or the events itself. A discrete-event simulation can be viewed as a sequence of event computations, with the computation of each event is assigned to a time stamp or simulation time. Thus each event computation can change the state variables or initiate new events. A discrete-event simulation system refers to the model of the physical system together with the simulation executive comprising of the event management list and simulation time advancing mechanisms.
An execution of the collection of such discrete simulation systems simultaneously makes the distributed simulation systems. A key aspect of a distributed simulation systems is the execution of various simulations simultaneously to optimise the usage of processors, memory, input and output devices, as well aiming at the synchronization of these different simulations. Typically distributed simulation refers to the technology concerned with executing computer simulations over computing systems containing multiple processors which may be using tightly coupled multiprocessor systems or workstations interconnected via a network (e.g., the Internet) and so on. The key advantages for opting distributed simulation systems are to minimize the model execution time, integrate simulation running on different platforms (interoperability and reuse), enable geographical distribution, for scalable performance, and fault tolerance ultimately enabling a higher performance computing. The execution of the different agent-based automata involve the automaton to change as per the transition rules as event lists with specific time advancement mechanisms in iterations. And so, the collection of all such agent-based models with the CA model is treated as distributed simulation systems.
The forthcoming chapter discusses the general framework for the integration of the agent-based models with the CA model.