This preprint should be cited as follows:
Green, D.G. (1994). A Web of SINs - the nature and
organization of Special Interest Networks.
A Web of SINs - the nature and organization
of Special Interest Networks
David G. Green
Information Technology
School of Environment and Information Sciences
Charles Sturt University
PO Box 789 Albury NSW 2640 AUSTRALIA
Email: dgreen@csu.edu.au
A Special Interest Network (SIN) is a set of network sites ("nodes")
that collaborate to provide a complete range of information activities
on a particular topic. SINS are emerging as an important new paradigm
for large scale collaboration on the Internet. Coordination
is achieved through logical design, automation, mirroring, standards,
and quality control. To be successful, SINs should strive to provide
reliable, authorative information services, to encourage
participation, and to accommodate growth.
The introduction of new protocols, especially Gopher and World Wide Web,
has led to an information explosion on computer networks around the globe.
Driven by a rapid growth in the number of users the Internet is rapidly
becoming the world's most important means of scientific information
exchange. Perhaps the most significant effect of these developments is
that they are beginning to change the very ways in which we carry out
many activities, such as research and teaching. Here I propose a model
- the "Special Interest Network" (SIN) - as a paradigm for large
scale collaboration and communication on the Internet.
As the volume and variety of network information grows, several trends,
needs and possibilities are increasingly evident. For instance,
perhaps the greatest immediate impact of the World Wide Web is that
it has makes network publishing a viable enterprise. The advantages
include instant, world-wide availability, hypertext and multimedia
content, and extreme flexibility in the material and format of
publications. Besides traditional books and articles, for instance,
we can now potentially publish data, software, images, animation
and audio.
There is a growing trend in many areas of research towards large scale
projects and studies that involve contributions from many sources
(Green,
1993a). Also, there is no need for a "publication" to be stored all
in one place. For instance, acting independently many Web sites have put
together national or regional guides.
Many of these documents, such as the
Guide to Australia integrate information from many
different sources.
In turn these documents are now themselves being merged to form
encyclopaedic information bases, such as the
Virtual Tourist.
There are also great advantages in publishing raw data, as well as the
conclusions of scientific studies. In many cases data that are gathered for
one purpose can be recycled and, combined with other data, add value to
related studies. Perhaps the most prominent example is the growth of molecular
biology databases. International databases, such as Genbank (Bilofsky & Burks,
1988) and EMBL (Cameron, 1988), are public compilations consisting
of contributions from thousands of scientists. Attempts are now underway to
expand this practice into other areas, such as biodiversity
(e.g. Burdet, 1992; Canhos et al., 1992;
(Green, 1994;
Greuter, 1991).
The trends described above have made several
needs increasingly obvious. These include:
- Organization -
Ensuring that users can obtain information easily and quickly.
Indexing services, such as Archie, Veronica and Jughead, have
been enormously useful, but are becoming increasingly difficult
to use, and maintain, as the sheer volume of information grows.
Subject indexes that point to sources of information on particular
themes are becoming increasingly important in the organization
of network information.
- Stability -
Ensuring that sources remain available and that links do not go "stale".
Rather than gathering information at a single centre, an important
principle is that the site that maintains a piece of information should
be the principal source. Copies of (say) a dataset can become out-of-date
very quickly, so it is more efficient for other sites to make links
to the site that maintains a dataset, rather than take copies of it.
- Quality Control -
Ensuring that information is valid, that data are up-to-date and accurate,
and that software works correctly.
- Standardization -
Ensuring that the form and content of information make it easy to use.
A Special Interest Network (SIN) is a group of people and/or
institutions who collaborate to provide information about a
particular subject. The main functions of a SIN fall into the
following four headings:
- Publication - the SIN publishes information on the
specialist topic. Besides articles and books in the traditional sense,
publications can also include datasets, images, audio, and software.
SINs adopt the fundamental principle that the supplier of a piece
of information is also the publisher. That is, rather than take
(say) data from many different sites and place it all on a single
server, each site runs its own server and publishes its own data.
The logical endpoint of this trend would be a server on EVERY
computer, with every individual user being his/her own publisher!
- Virtual Library - the SIN provides users with access
to information on the specialist topic. Besides information stored
on-site, there are links to relevant information elsewhere.
- On-line Services - the SIN might provide relevant services,
such as analyzing data, to its users.
- Communications - the SIN provides a means for people
in the field to keep in touch. This might include mailing lists,
newsgroups, newsletters, and conferences.
SINS consist of a series of participating "nodes" that each contribute
to the network's functions. More specifically the nodes carry one or
more of the following:
- Accept and store relevant, contributed material;
- Provide some form of public access for users;
- Provide some unique information, or mirror other sites;
- Provide organized links to other nodes;
- Coordinate their activity with other nodes.
For research activity, SINs are the modern equivalent of learned societies.
Some may even be the communications medium for societies (e.g. Burdet, 1992).
We can also consider SINs as a logical extension of newsgroups and bulletin
boards. Namely, they aim to provide a complete working environment for their
members and users. SINs differ from SIGs ("special interest groups")
in two important ways. First SIGs are usually part of larger organizations.
The second, and greater, distinction lies in the use of networks.
Whereas a group usually has a focus, SINs are explicitly decentralized.
A good example of a SIN is the
European Molecular Biology Network.
EMBNet is a special interest network that serves the European molecular
biology and biotechnology research community. It consists of nodes operated
by biologically oriented centers in different European countries.
It features a number of services and activities, especially genomic databases
such as EMBL (Cameron, 1988).
The following features characterize most large special interest
networks. They also provide guidelines for setting one up.
- Need - The SIN serves a need that is not being met
by other means, or provides a better (more comprehensive, accurate
or reliable) set of data than is available from other sources.
- Coordination - a coordinating centre or syndicate
organizes the network, receives and processes new entries,
and communicates relevant news to its users.
- Support - There is a body of users who are willing and
able to help to establish and manage the network's information
activities (managing databases, editing publications, moderating
newsgroups, mailing lists, etc.).
- Participation - Anyone may contribute items to the
information base. Major SINs announce new entries via special
newsgroups or mailing lists. Contributors carry out all editing of
their entries, including formatting, correcting and updating them.
- Access - Anyone may access, copy or use the information
at any time. Normally access is via a computing network using a
standard protocol.
- Standards (see later) - Contributors must use standard
fields and attributes in submissions (e.g. Croft, 1989). These
standards must be well defined and should be publicized as widely
as possible. For data they are often expressed as a submission form
(electronic, printed, or both) that is filled in by contributors.
- Format - Textual data (including bibliographies, mailing
lists, etc.) are normally submitted as ASCII files with embedded tags.
The Standard Generalized Markup Language (SGML) provides a flexible
medium for "marking up" information for a variety of purposes.
The Hypertext Markup Language (HTML), which is an SGML application,
is used for formatting documents for distribution via the World Wide Web.
However there are many advantages in marking up documents using
structural tags, rather than HTML's predominantly formatting tags.
This practice allows great flexibility in the way servers access
information. For instance, equivalent sections (e.g. bibliographies)
can be automatically extracted from many different files, combined,
reformatted and delivered as a Web document.
On any particular node databases can be stored using any database
software, provided that a suitable network gateway can be provided.
Utilities for SQL/HTML conversion are now widely available, for instance.
Images should be in one of the common formats in use, such as
GIF (Graphic Interchange Format) or JPEG (Joint Photographic Experts Group).
- Quality control (see later) - Users need some guarantee
that data provided in a database are both valid and accurate (Green,
1991, 1992). Quality control checks can be applied by database contributors,
coordinators, and users (see later).
- Attribution - Every item of information should include an
indication of its contributor. This is essential to the notion that
contributions are a form of publication.
- Agreements - There is an explicit list of terms and conditions.
Typically, users agree to acknowledge the sources and to waive liability
for any use they make of the data. Contributors agree to place their data
in the public domain. The organizers agree to abide by the usual
conditions for publications, such as referring corrections or changes to
the contributors. Everyone agrees not to sell or charge for the data.
- Automation - as many operations as possible
(e.g. logging and acknowledging submissions) should be automated (Fig. 1).
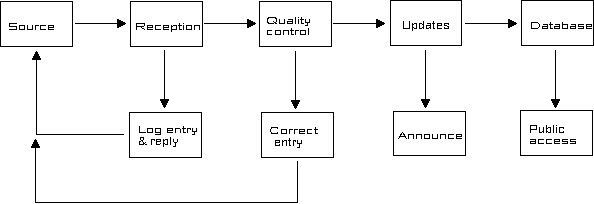
Fig. 1. Stages in the publication of information on a node of a SIN.
As many steps as possible should be automated.
An information system that is distributed over several sites (nodes)
requires close coordination between the sites inolved.
The coordinators need to agree on the following points:
- logical structure of the on-line information;
- separation of function between the sites involved;
- attribute standards for submissions (see below);
- protocols for submission of entries, corrections, etc.;
- quality control criteria and procedures (see below);
- protocol for on-line searching of the databases;
- protocols for "mirroring" the data sets.
For instance, an international biodiversity database project might
consist of agreements on the above points by a set or participating
sites ("nodes"). Contributors could submit their entries to any nodes
and each node would either "mirror" the others or else provide on-line
links to them.
The use of information often falls into the following
four-stage cycle of activities:
- asking questions,
- gathering relevant information,
- interpreting the information,
- disseminating the results.
SINs can assist at each stage of this "research" cycle:
- In the first stage, communication enables people concerned
with a particular topic to stay in constant touch with the relevant
user community. The benefits include the ability to relay questions
and initiate discussion of issues essentially in real time;
to enable those who need to ask questions to contact people
able to answer those questions;
to provide a forum for current issues to be discussed in a timely
fashion; and
to minimize unnecessary duplication of effort.
- In the information gathering stage, not only can uses more
effectively reach sources of relevant information, but they can
also help each other by indexing any new resources that they may
discover in the process or by adding fresh data items to
existing repositories.
- In the interpretation stage, users may be able to access useful
software, search bibliographies, or seek advice from colleagues.
- In the dissemination phase, users will be able to publish their
results to a very wide audience very quickly. In scientific research
these practices are already widespread in many fields (e.g. physics)
and several network-based journals already exist on Internet
(e.g.
Complexity International).
Most parts of the world are now linked by the Internet (Krol, 1992),
which is a computing "network of networks" that links together
literally millions of computers around the world.
A few of the services currently available include:
Gopher, WAIS,
World Wide Web, FTP,
Usenet News, Telnet,
Hytelnet (a bibliographic protocol for libraries, a library SIN),
X.500 and network resource location services, such as Archie,
Veronica and Jughead, for searching the network. For details of
available services, see for example,
The Biologist's Guide to the Internet.
Until recently "File Transfer Protocol" (FTP) was perhaps the most popular
method of providing information over the Internet. Under "anonymous FTP"
users log in to a host site across the network (using the name "anonymous"
and giving their email address as a "password"). They are then free to
retrieve any files from the host's public directories of information.
Many sites provide services to "guest" users via the telnet protocol.
Under telnet, users log in to a host site using a publicized guest
account. This account allows them to use services that the host makes
available to the public, such as querying a database or running certain
programs (e.g. public gopher or web clients).
Listervers provide public mailing lists. Subscribers join a list
by mailing a subscription "subscribe list_name user_name" (with the
appropriate names inserted, e.g. subscribe biodiv-l Fred Nurk) to the
server listserv@host_name (e.g. listserv@ftpt.br). The listserver
program adds their name to the mailing list. Subscribers can
communicate with everyone on the list by sending messages to
the address list_name@host_name (e.g. biodiv-
l@ftpt.br), which is
then broadcast to all members of the list.
WAIS ("Wide Area Information Servers") is a client-server protocol to
search for and retrieve files, based on full-text indexing of their
contents or titles. A common application is a "waisindex", which is
often available via gopher or web servers.
Gopher is a client-server protocol for retrieving multimedia information
automatically via a system of menus. Developed at the University
of Minnesota, Gopher revolutionized environmental information
by enabling computer-non-literates to access network information such
as FTP and WAIS (including images and sounds) without having to know
about the usual process. It now has literally millions of users
world-wide.
The key factors in the success of Gopher are its simplicity - just
point and click on a menu - and the availability of "client" software
for all of the most commonly used computing platforms. Previously,
using the Internet had required a fair measure of computer literacy.
Gopher made it possible for many people to explore "The Net" for the
first time.
Furthermore, gopher server sites are very easy to set up and maintain;
basically ascii files are formatted and placed in a gopher file system.
However more sophisticated implementations involving such things as
gateways to SQL databases are also possible.
The
World Wide Web (WWW) originated at
CERN in Switzerland.
Like Gopher, it operates on a client-server basis. The underlying
protocol is the HyperText Transfer Protocol (HTTP). Like Gopher,
WWW supports multimedia transactions. But rather than menus,
"The Web" deals primarily with hypertext documents.
These documents are formatted using the "Hypertext Markup Language"
(HTML) which allows limited text layout and formatting, and
the inclusion of hypertext links. These links are presented
in the form of selectable highlighted terms or images embedded
directly within the text that lead to other documents, images,
etc., which may themselves contain embedded hyptertext links.
Selecting one of these links tells the software to retrieve the
selected item for display, from wherever in the world it is stored.
The items may be documents, images, audio, or even animation.
WWW's hypertext formatting language (HTML) is an application of
SGML (see earlier). The freeware program RTFtoHTML converts Rich
Text Format (an output option on many wordprocessors) to HTML and
macros for converting text to HTML are available for MS Word.
The HTML browser tkWWW (freeware for Unix/X11) includes a WYSIWYG
editor for HTML.
During 1993 World Wide Web (WWW) began to have a profound effect
on the academic community. Like Gopher, participation on the "Web"
is growing exponentially (doubling time is at present 3 months).
The stimulus of the explosion was NCSA's release of a new program
(Mosaic) that realized the full potential of WWW's hypermedia
capability. NCSA Mosaic is now available under X-Windows,
Macintosh and DOS-Windows systems. Important features of
Web browsers (first introduced by NCSA's program Mosaic) include:
- they permits browsing of ALL of the main network protocols
(FTP, WAIS, Gopher, telnet, etc.);
- they permits both text formatting and images that are embedded
directly within text, so providing the capability of a true
"electronic book";
- they integrate freely available third party display tools
for image data, sound, Postscript, animation, etc.
- they permits seamless integration of a user's own local data
(without the need of a server) with information from servers
anywhere on the Web;
- the forms interface allows users to interact with
documents that appear as forms (including buttons, menus, dialog
boxes) which can pass complex queries back to the server.
- the map interface allows users to query a map
interactively. This would allow (say) a user to get information
about different countries just by clicking on a world map, in
GIS-like fashion.
- the authorization feature provides various security
features, such as restricting access to particular information,
passwords etc.
- the SQL gateway allows servers to pass queries
to databases. Such gateways are already implemented for many
databases (e.g. Australian plants, DNA sequences).
- the ability to run scripts or programs on the server and to
deliver the results to WWW.
- the ability to include files dynamically and thus build up
and deliver documents "on the fly".
Although SINS could (and no doubt will) be organized in many different ways.
Using the example of running a public database, the scheme outlined below
recommends mechanisms that are designed to distribute the workload,
encourage participation and to accommodate growth:
- One node acts as a secretariat for the network.
- Each node serves some special function, such as acting
as coordinating centre for one or more SIN projects, or acting
as a regional centre.
- Each node mirrors a set of basic documents and/or menus
that define the basic services offered by the SIN.
- Maintenance of each project and/or document is supervised by a
coordinating centre (not necessarily the same for every activity).
- Material for publication may be submitted to any node (or perhaps
to some subset).
- The coordinating centre for a given project regularly
harvests incoming items from other nodes, carries out quality
control procedures, and prepares updates.
- Each node carries out a mirroring operation regularly
(say once per day) to retrieve up-to-date, local copies of
updates and other new information from coordinating centres.
Many of the above steps will be automated. "Mirroring" is the process of
duplicate of a set of information that originates from another site.
Whereas it is generally better to provide a pointer to the site that
maintains an item of information, it is desirable to mirror any information
(e.g. a "home" page for the SIN) that is frequently used, especially
to reduce international traffic. Mirroring is also desirable in case of
disk crashes or breaks in entwork connections.
Coordinating and exchanging scientific information are possible only if
different data sets are compatible with one another. To be reusable, data
must conform to standards. The need for widely recognized data standards
and data formats is therefore growing rapidly. Given the increasing
importance of network communications (Green, 1993a, 1993bb) new standards
should be compatible with network protocols.
To be reusable, data must conform to standards. Standards play a crucial
role in coordinating activity. We need to develop two main kinds.
- Attribute standards define what information to collect. Some
information (e.g. who, when, where and how) is essential for every data
set; other information (e.g. soil pH) may be desirable but not essential.
- Quality control standards provide indicators of validity,
accuracy, reliability or methodology for data fields and entries (see below).
Examples include indicators of precision for (say) spatial location,
references to glossaries or authorities used for names, and codes to
indicate the kinds of error checks that have been performed on the entry.
- Interchange standards specify how information should be laid
out for distribution.
Users need assurance that data is correct, that software works,
and that articles contain valid information. Because anyone can
open a network site and release anything they like, quality is
not assured. Users therefore tend to refer to sites that act as
an authoritative source or some other guarantee of quality.
For this reason users usually prefer sites that are well-managed,
well-organized, or belong to respected institutions.
To ensure validity, molecular biology databases use the simple,
but effective criterion of publication in a refereed journal.
Many other approaches can be used. For example one might insist
that a description of methodology accompany each data set that has
not been published (say) in the scientific literature. Alternatively,
a site might accept all contributions and categorize them on the
basis of the evident quality of information.
Whatever criteria are used it is desirable to include indicators of
reliability for the information in the attribute standard. Ideally
every item of information should include a tag denoting accuracy or
validity. Quality control fields need to include information about
what error checks have been applied to ensure that the values have
been recorded and entered correctly.
The compiling agent can apply consistency and outlier checks to filter
out errors that may have been missed earlier (Green 1991, 1992).
If the data incorporate sufficient redundancy, then consistency checks
can reveal many errors. Does the named species exist? For instance,
does the location given for a field site lie on land? and within the
country indicated? If the database maintains suitable background information,
then outlier tests can reveal suspect records that need to be rechecked.
For instance if a record indicates that a plant grows at a site that
has significantly lower rainfall than any other for that species,
then the record needs to be checked in case of error. Both sorts of
checks can be automated and are now routine for census data. They
have recently been applied to herbarium records and other
environmental data (e.g. Chapman, 1992).
The general publication procedure (Fig. 1) includes a quality control
step. When a contribution is received the editor applies tests to
ensure that the information conforms to the standard and to check
for any obvious errors. For text material this quality control
process might simply be a careful reading of the ms. If any faults
are detected, the information is returned to the source for
correction. After this initial checking, new items are placed in
an updates area (Fig. 1) and users are invited to submit comments
about them. After suitable checks, and corrections by the
contributor, the new entry is transferred to the database proper.
An important activity of a SIN is for many sites to contribute to build
a joint database that is searchable across the network. A network database
can have four different levels of distribution:
- Centralized - the entire database resides on a single server;
other sites point to it. This is the most common form of network database.
- Distributed data, separate indices at each site -
The database consists of several component databases, each maintained
at different sites. A common interface (e.g. a WWW document) provides
pointers to the components, which are queried separately. This form of
loose integration is common using Gopher, WAIS and WWW.
- Distributed data, single centralized index - The data consists
of many items, which are stored at different sites but accessed via a
database of pointers maintained at a single site. Several forms of
network indexing, such as Veronica, Jughead, WAIS, and several
WWW harvesters support this form of integration.
- Distributed data, multiple queries - many component databases
are queried simultaneously across the network from a single interface.
At present no common protocol publicly available supports such a
flexible form of database integration, but it is possible to use
proprietary software from a single supplier.
An important function of a special interest network is to provide a
virtual library.
That is, it should provide organized links
to relevant information, wherever this information resides on
the Internet. The biggest and best known virtual library is the
World Wide Web Virtual Library, which is operated by
CERN
The logical design of the system could be based
around major projects & themes and the library can be compiled
and maintained in several ways:
- Members can submit "hotlists" of thematic pointers to a
coordinating centre for editing;
- An automatic registration service (e.g. via email or as a WWW form)
can be available for people to submit relevant links information, which
is then processed by scripts on a network server.
The above information could be made available via a series of
menus and pages available on the Internet via Gopher,
World Wide Web and other suitable protocols. Copies of the main
pages and hierarchy of documents could be available at each node
in the network.
This will require a regular "mirroring" process to ensure that all
nodes are kept up to date. It is very important to ensure that all
information items in this library are visible at all nodes and not
just visible as an isolated reference at a particular site.
Network publications can range from familiar paper items - books,
journals, news magazines - that are simply transferred to electronic
form to novel productions, such as image databases or thematic
compilations of pointers to items stored at many different sites.
An important principle in network publication is that the site that
maintains an item of information publishes the information. This rule
applies esecially to items that are updated regularly. Secondary sources
(other sites that want to provide their users with access to the item
concerned) should adopt one of two options: either provide a link to
the primary site, or else mirror the original by downloading copies
at regular intervals. These practices ensure that users always have
access to the most up-to-date information available.
One approach to publishing that a SIN can adopt is simply to register
relevant existing activities. This benefits both the SIN as a whole
and the publishing site:
- individual sites can gain an international "stamp of approval",
and world-wide collaboration, for particular projects by having them
recognized by the SIN;
- a SIN can incorporate many different projects, each supervised by
a separate node, and no single agency needs to bear the full burden
for any particular project.
- a SIN or site can continue to focus on its own particular area of
specialization or expertize and still provide access to information held
at other sites.
Automation is a key element in making a SIN viable. The aim is
to reduce the workload and human involvement in creating and
maintaining information, and hence costs, for participating nodes.
For example, publishing submitted material (whether text, data,
images etc) involves several steps (Fig. 1). As many as possible
of these steps should be automated. For instance, storing,
registering and acknowledging incoming material are routine
procedures that are time-consuming if done "by hand".
Once the necessary scripts and programs have been developed, they could
be provided with other standard files as astartup package to new nodes.
In many cases the scripts and programs needed to automate particular
procedures already exist and are freely available on the Internet.
The notion of SINS as described here derives from three sources.
First, as manager of a network information server I was prompted
to develop the idea after observing the ways in which various sites
had begun to coordinate their activities on particular topics.
It seemed to me that SINS have the potential to fill both the role
of learned societies as authoritative bodies, and of libraries as
stable repositories of knowledge and information.
Second, the evident success of molecular biology databases and physics
preprint services suggests that the underlying principles can be
extended both to other fields and to other areas of activity. Across the
entire range of science, for instance, observations and experiments
yield a wealth of raw data which, if suitably organized, can add value
to future studies.
Finally there is the problem of how to organize an exploding pool of
information on the network. Librarians have struggled with this problem
for centuries. Whilst their solutions are useful, the information
explosion on the network poses problems never encountered before:
the sheer volume of information, rapid turnover and change (especially
the need to maintain information), and the flexibility of hypertext and
multimedia. The SINS approach provides a user-driven solution, in which
groups of people interested in a particular topic organize and index
information in ways that they find most useful.
Various projects are putting into practice the SINS concept, as outlined here.
For example, FireNet,
for example, is a SIN concerned with all aspects of landscape fires
(Green et al., 1994)
and the Biodiversity Information
Network (BIN21) has now organized its network activity as a SIN
(Green and Croft, 1994).
These and other similar activities have provided many useful lessons
about putting the SINS idea in practice. I have tried to incorporate some
of this practical experience into the above account. The interest shown in
such groups encourages my belief that the SINS approach is a very fruitful
way to organize activity via the Internet.
To put current developments into perspective, we can consider the changes
that have taken place in the way that scientific results are disseminated.
We might term the Sixteenth and Seventeenth Century was the era of
correspondence between great scholars. The Nineteenth Century can be
classed as the era of the great societies and the Twentieth as the era
of the great journals. The Twenty-First Century will surely become the
era of the knowledge web and I expect that SINS, whatever form they may take,
will play a major role in its organization.
- Bilofsky, H. S. & Burks, C. (1988).
The GenBank genetic sequence data bank.
Nucl. Acids Res. 16: 1861-1863.
- Burdet, H. M. (1992).
What is IOPI?
Taxon 41: 390-392.
- Cameron, G. N. (1988).
The EMBL data library.
Nucl. Acids Res. 16: 1865-1867.
- Canhos, V., Lange, D., Kirsop, B.E., Nandi, S., Ross, E. (Eds). (1992).
Needs and Specifications for a Biodiversity Information Network.
United Nations Environment Programme, Nairobi.
- Croft, J.R. (1989).
Herbarium information standards and protocols for interchange of data.
Australian National Botanic Gardens, Canberra.
- Goldfarb, C. (1990).
The SGML Handbook.
Oxford: Oxford University Press.
- Green, D.G. (1993a).
Databasing the world.
INQUA - Commission for the Study of the Holocene, Working Group
on Data-Handling Methods 9, 12-17.
- Green, D.G. (1993b).
Hypermedia and palaeoenvironmental research.
INQUA - Commission for the Study of the Holocene, Working Group
on Data-Handling Methods 10, 11-14.
- Green, D.G. (1994).
Databasing diversity - a distributed, public-domain approach.
Taxon 43, 51-62.
- Green, D.G. and Croft, J.R. (1994).
Proposal for Implementing a Biodiversity Information Network.
In Linking Mechanisms for Biodiversity Information.
Proceedings of a Workshop for the Biodiversity Information Network,
Base de Dados Tropical,
Campinas, Sao Paulo, Brasil.
- Green, D.G., Gill, A.M. & Trevitt, A.C.F. (1993).
Wildfire - Quarterly Bulletin of the
International Association of Wildland Fire 2(4), 22-30.
- Greuter, W. (1991).
Draft lists of names in current use: first management progress report.
Taxon 40: 521-524.
- Krol, E. (1992).
The Whole Internet Guide and Catalog.
O'Reilly and Associates.
- Smith, J. & Stutely, R. (1988).
SGML: the Users' Guide to ISO 8879.
New York/Chichester/Brisbane/Toronto:
Ellis Horwood Limited/Halstead Press.