Proposed operation of a virtual library
David G. Green
Environmental and Information Science,
Charles Sturt University, Albury NSW 2460 Australia
Email: dgreen@csu.edu.au
Outline
Introduction
Coordinating centre
The role of editors
Gathering records
Records
Logical design
Maintenance
Automation
Example
References
Introduction
A virtual library is an organized set of links to items
(documents, software, images, databases etc) on the network.
The purpose of a virtual library is to enable users of a
site to find information that exists elsewhere on the network.
Virtual libraries (VL) are a natural growth of the ability of modern
client server protocols (especially HTTP and Gopher) to provide
seamless links to information anywhere on the Internet. The first
VLs were menus of links about a particular topic. They were thrown
together by site managers to assist the users find items of interest.
As the sheer volume of information has grown this approach is
increasingly difficult to maintain. Automation, cooperation and
more flexible designs are becoming essential.
Much attention has focussed on the development of automated
systems for indexing network information. Many of these systems
are non-selective in building indexes. Others are designed to
index information only for a particular suite of sites. However the
real advantage of a virtual library, especially one associated with
a special interest network, is that it focuses on material relevant
to a particular topic. The design I outline here is intended to be
a fruitful mixture of automation with human participation, of
flexible searching with "guided tours" of the information.
Important issues in running a virtual library include finding
the "records" (i.e. the links to relevant interest), managing the
records, and providing access to the records. I assume throughout
that the VL is being developed by a Special Interest Network (SIN)
(Green & Croft, 1994). Any or all nodes in a SIN can participate
in the management of its virtual library.
Coordinating centre
One node of the network acts as the coordinating centre for the VL.
(The work might be divided amongst several nodes).
Its main role is to collate and process records. If the VL includes
a central main database, this would normally be maintained by the
coordinating centre.
The role of editors
The virtual library is managed by a team of editors; there may
be one or many. Each editor has responsibility for (say) a given
theme or topic. There is a coordinating editor (i.e. at the VL
coordinating centre) who supervises the merging of incoming entries.
General editing functions (see details below) include:
- supervising automated searches;
- evaluating incoming items;
- editing email and web submission forms;
- locating and entering new relevant entries;
- assessing quality incoming entries;
- supervising the validation and merging procedures;
- creating views;
- responding to user queries.
Gathering records
An important principle in operating a VL is to distribute the
work as widely as possible. Ideally, the editors should have to
do little searching for records themselves. There are three main
sources of records:
- Manual - direct collation of records by the editors
(this is still the MAIN method of compilation at most sites);
- Passive - public submissions from users via email or
WWW forms;
- Active - automated searches using Web walkers, worms,
spiders, harvesters, etc.
Records
The records maintained by the library must include enough
information to identify what the item is, where it is, and how
to maintain it. The submission form provides the following fields:
- URL for the source
- A title for the item
- A brief informative description of the item
- Contact for the item (usually the site maintainer)
- About this submission
- Indexing Details
- Standard keyword/headings
- Other keywords
- Datestamp for the record
Logical design
As with any library, the records in a VL need to contain enough details
to allow them to be indexed adequately. Full text indexes of
filenames (cf Archie) or titles (cf Veronica) are useful, but can be
both unreliable and wasteful. It is therefore useful to include a
series of keywords with each record. By drawing keywords from a
standard list, and allowing that list to be augmented by user-supplied
terms, the VL can build up a rich set of classifications. These
categories will also reflect the thinking of its users.
As conceived here, a VL consists primarily of files containing lists of
records, with each record including the information described above.
For maintenance purposes, one effective design is to build the files
chronologically - e.g. by datestamping and storing the updates file
(see below) for each month. All methods of accessing records (e.g.
a word search) simply filter these files.
There are two chief ways of retrieving the records. Searches filter
the stored records to retrieve those that satisfy a specified search
criterion. The VL can also provide views of the information.
Views are collated subsets of records. They are prepared by the editors
(or interested users) to help guide users to relevant information.
Most early VLs were really just views, but without an underlying
database structure. Views can either be simple HTML documents
containing items copied from the database, or else pre-canned
filters for pulling out and displaying records from the database.
Some initial views (most still need to be constructed) will
include the following:
The heading "biological levels" would divide material according
to the scale involved. Hence sub-headings might include:
molecular biology, genetics, population biology, ecology, etc.
The heading "themes" would include a wide range of subject
headings, such as:
- Bibliographies
- Biodiversity programs and project descriptions
- Conservation information and programs
- Contact registers for organizations, people and projects
-
DNA/molecular/genetic
-
Ecosystem history and historical reconstruction
- Educational materials
- Environmental background materials
- Environmental legislative information
- Genetic resources information
- Geopolitical information
- Global climate change information
- On-line databases of site, survey and point locality information
- Regional information
- Research and management tools
- Software
- Species distributions
- Systematic and phylogenetic reconstruction
- Taxonomic and nomenclatural
Maintenance
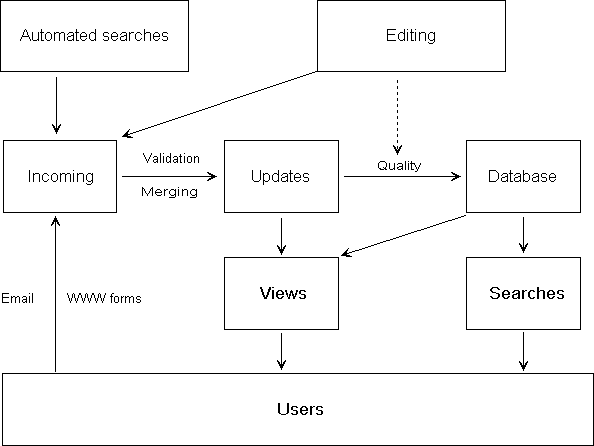
Fig. 1
Flow control sequence for adding new items to a virtual library.
See the text for further explanation.
Below is an explanation of the terms used in the procedure.
Not shown are some of the routine housekeeping procedures,
such as regular fingering to ensure that links remain current.
The arrows denote direction of movement for files or information.
- Automated searches
- These are active searches of the network for relevant
material using self-managing software. Several such programs now exist;
examples include "web-walkers", "worms", "spiders", "harvesters" etc.
They can be tuned to search either the entire Web, or else a selected
set of "interesting" sites.
- Editing
- This denotes people who manage the virtual library (see above).
- Incoming
- New entries go immediately into a file (e.g. "vl_incoming")
on the node where they are received. The entries are stored in
SGML format (Smith & Stutely, 1988; Goldfarb, 1990) and are
appended to the file as they arrive. Each node has its own
incoming file(s). There may be separate incoming files for
automated searches, editorial entries, and user contributions.
The entries are flushed after processing.
- Updates
- The updates file is maintained by the VL coordinating centre.
The other nodes either mirror it or else provide a link. This file
contains new VL items in SGML format following validation and merging.
It is visible to users. Users may see it as a document called "What's New",
rather than "updates".
- Database
- The database is the accumulation of all items stored in the
virtual library. The exact nature of the database may vary according
to available software. Also the database may be centralised, or else
distributed amongst various nodes. One method of storage would be to
archive the update files at regular intervals (e.g. monthly) and
develop indexes that poll all of the archived files.
- Views
- Views are HTML pages (or metapages) created by editors to
help users to access VL entries in a systematic way, rather than via
database queries. (At present most virtual libraries consist purely
and simply of views). Each view is maintained by a particular editor
at a particular node, and is referenced (or mirrored) by other nodes.
- Searches
- Searches are on-line queries of the main VL database.
Potential queries could include full text indexing or indexing by
fields (e.g. keywords). The normal method would be an HTML form,
but alternatives might include email or gopher.
- Users
- Users can read entries in the updates file and in the main
database. They can browse the database either by running database queries,
or by looking at views prepared by the editors.
- Merging
- At regular intervals the VL coordinating centre downloads
the incoming files from all nodes and merges the information into a single
file. Duplicate entries are removed. The merged file is processed
for validity and quality to produce the updates file.
- Validation
- New entries are fingered to ensure that they exist and
that the given details are correct.
- Quality
- Editors assess incoming entries for quality
(Chapman, 1992). Some essential considerations include:
- relevance;
- reliability/validity;
- uniqueness (does the same item exist elsewhere?)
- stability of the source site;
- completeness of the entry (are vital details missing?)
- WWW forms
- The VL provides a WWW form to allow users to submit entries
to the VL. Acceptance of submitted entries is not automatic, but subject
to quality and other considerations by the editors. The forms are fed
to a script that writes them in SGML format (Smith & Stutely, 1988;
Goldfarb, 1990) to the incoming file.
- Email
- Users may also submit entries for consideration by email,
using a pro forma. The processing is similar to that for forms.
See below for an example.
<RECORD DATE="Fri Apr 29 12:59:44 1994">
<source_url>http://life.anu.edu.au/</source_url>
<source_title>ANU Bioinformatics service</source_title>
<item_description>Virtual library of biodiversity information.
Includes home pages for International Organization
for Plant Information (IOPI) and Biodiversity Information
Network (BIN21). </item_description>
<contact_name>Dr David Green </contact_name>
<contact_mail>web-manager@life.anu.edu.au</contact_mail>
<submit_name>David Green </submit_name>
<submit_mail>david.green@anu.edu.au</submit_mail>
<themes>molecular</themes>
<themes>history</themes>
<themes>education</themes>
<themes>climate</themes>
<themes>software</themes>
<themes>distributions</themes>
<themes>systematics</themes>
<themes>taxonomic</themes>
<themes_other></themes_other>
</RECORD>
Fig. 2
Example of a virtual library entry in SGML format.
Automation
It is desirable to automate as much of the operation of the VL
as possible. Many of the specific procedures have already been
mentioned; they include most of the operations shown in Figure 1.
Tools for some operations already exist in the public domain
(e.g. mirrors, harvesting). Others should be developed and
distributed to all nodes. The language
Perl
(Schwartz, 1993; Wall & Schwartz, 1991).
Example
Here is an example of a submission form for a virtual library.
Virtual Library submission form
References
- Chapman, A.D. 1992.
Quality control and validation of environmental resource data.
In Data Quality and Standards. Proceedings of a seminar
organised by the Commonwealth Land Information Forum, Canberra,
5 December 1991. Australian Land Information Group, Canberra. 16 pp.
- Goldfarb, C. 1990. The SGML Handbook.
Oxford: Oxford University Press.
- Green, D.G. 1993.
Databasing the world.
INQUA - Commission for the Study of the Holocene, Working Group
on Data-Handling Methods 9, 12-17.
- Green, D.G. and Croft, J.R. 1994.
Proposal for Implementing a Biodiversity Information Network.
In Linking Mechanisms for Biodiversity Information.
Proceedings of a Workshop for the Biodiversity Information Network,
Base de Dados Tropical,
Campinas, Sao Paulo, Brasil.
- Schwartz, R.L. 1993. Learning Perl.
O'Reilly & Associates, Sebastopol CA.
- Smith, J. & Stutely, R. 1988.
SGML: the Users' Guide to ISO 8879.
New York/Chichester/Brisbane/Toronto: Ellis Horwood Limited/Halstead Press.
- Wall, L. & Schwartz, R.L. 1991. Programming Perl.
O'Reilly & Associates, Sebastopol CA.